Triaging Priority-Zero Events

When a critical vulnerability hits, the instinctive question is: are we vulnerable?
That question matters, but how to answer it...
Triage cannot depend on perfect certainty
In a real incident, teams often cannot prove quickly that a vulnerable path is impossible. They may have incomplete asset data, unclear ownership, limited application knowledge, or scanner results that show presence without runtime context. In those situations, the decision should not wait for absolute proof. If the affected technology is present and exposure cannot be confidently ruled out, the safer assumption is that the organization is exposed.
Most teams know this intuitively. Not all have a consistent, structured way to work through it under pressure, when a KEV listing has just dropped and the CISO is in the channel asking for a status update. Organizations must have a defined decision path for triaging quickly, consistently, and defensibly.
A Framework for triage
The framework below structures the P0 triage decision into three sequential questions. Each one narrows the problem and determines the pace and character of the response.
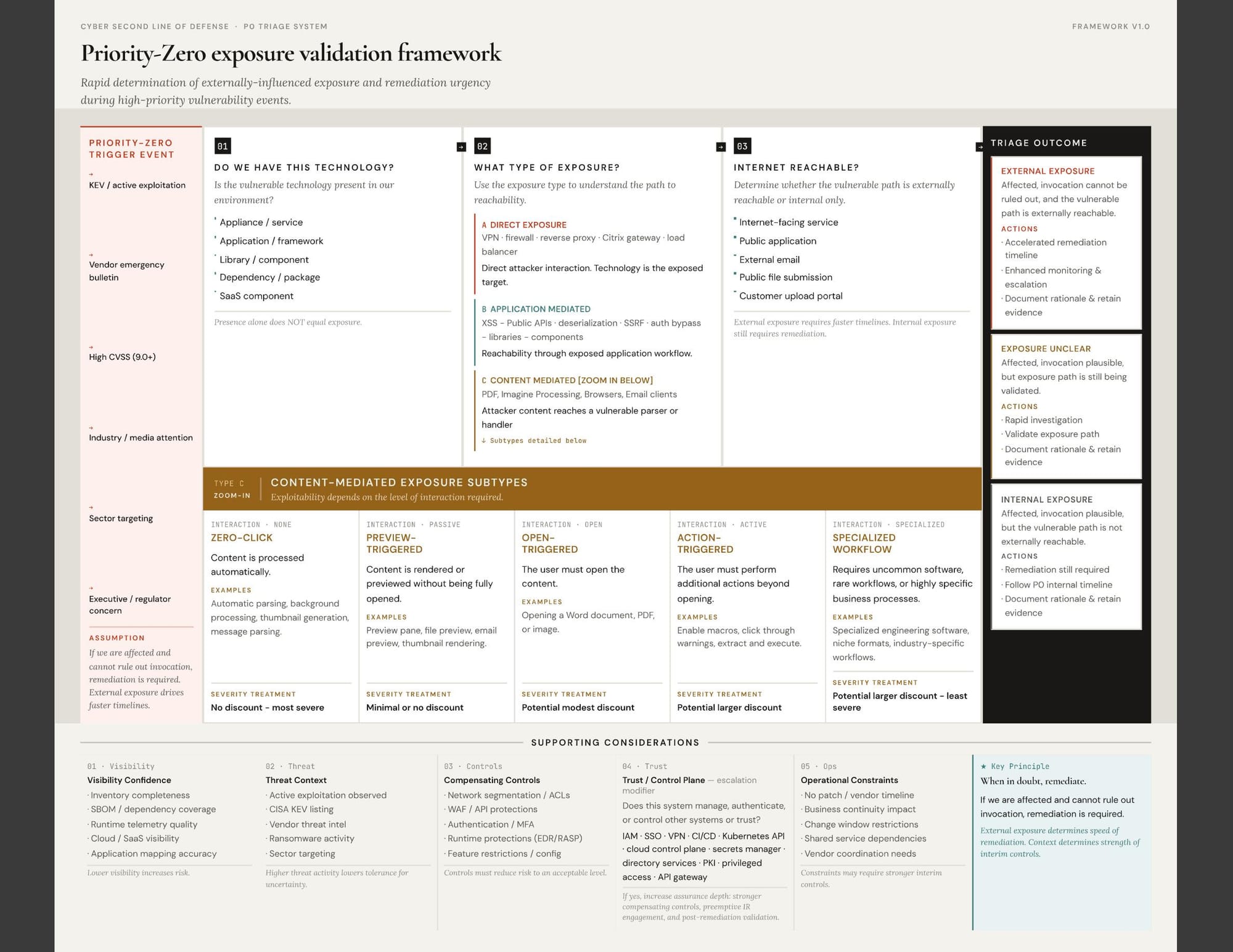
Question one: Are we affected?
Is the vulnerable technology present in your environment? This covers the full surface: appliances and services, application frameworks, libraries and components, dependencies and packages, SaaS components. A negative answer here ends the triage. A positive answer moves you to question two.
Question two: What type of exposure is this?
The exposure type determines both the evidence you need to gather and the confidence you can place in your initial assessment. Not all exposure is equal. The framework distinguishes three types:
- Direct exposure. The vulnerable technology is itself the target and is directly connected to the internet. Think network appliances, VPN concentrators, edge firewalls, and load balancers. The attacker reaches the vulnerable component without traversing application logic. The exposure path is unambiguous; the urgency is highest.
- Application exposure. Reachability runs through your public APIs or accessible application workflows. Attacker-controlled application inputs determine whether the vulnerable code path is triggerable. The exposure path requires more mapping but is often surfaceable from API inventories and application ownership records. The vulnerability may live in a library or framework invoked indirectly through application behavior. This is where uncertainty is highest and where SBOM coverage matters most. You often cannot determine reachability without tracing call paths through layers of abstraction.
- Content - mediated exposure: The vulnerability is exploited by attacker crafted content such as PDFs, word documents, image documents or browser activity. There are different degrees of user interaction required: a higher degree of required interaction should translate into a lower vulnerability severity.
- Zero-click: content is processed automatically without any user action. Treat as severe; no discount applies.
- Preview-triggered: the vulnerability fires through a preview pane, thumbnail generation, indexing, scanning, or background rendering. Treat as near zero-click.
- Open-triggered: the user must open the file, message, or link. A modest severity discount may be reasonable.
- Action-triggered: exploitation requires the user to enable macros, click through a warning, extract an archive, or install a font. A larger discount may be reasonable.
- Specialized workflow: the vulnerability requires uncommon software, a rare file type, or an unusual business process to reach. A larger discount applies, unless the target organization is the kind of environment where that workflow is routine or the attacker is conducting targeted operations.
Question three: Is the impacted technology internet reachable?
This is the question that governs remediation speed. Directly internet-facing technology, externally authenticated services, public API paths, and externally supplied content sources all carry different risk profiles than internal-only deployments. The framework maps these to three remediation outcomes: external exposure, which drives accelerated timelines according to P0 requirements; internal exposure, which still requires remediation but on the internal exposure timeline; and exposure unclear, which requires rapid investigation before a classification can be confirmed.
Supporting Considerations That Change the Calculus
Four variables cut across all three questions and can accelerate or tighten the response regardless of where a vulnerability lands in the framework.
Visibility confidence. If your inventory is incomplete, your SBOM coverage is thin, or your cloud and SaaS visibility is limited, a negative on question one is less reliable. Lower visibility confidence increases the effective risk of any triage outcome.
Threat context. Active exploitation observed in the wild, a CISA KEV listing, published proof-of-concept code, or sector-specific targeting all reduce tolerance for uncertainty. High threat context compresses the timeline for resolving exposure unclear states.
Compensating controls. Network segmentation, WAF coverage, authentication controls, and runtime protection can legitimately reduce risk while remediation proceeds. Controls must actually reduce risk to an acceptable level, not just exist on paper.
Control plane exposure. If the vulnerable component manages other principals or sits in your trust hierarchy -- certificate authorities, AD/LDAP, cloud control planes, API gateways, privileged access systems -- the stakes are higher and the compensating control bar is higher. These cases should trigger a separate escalation review regardless of where the exposure path classification lands.
The Takeaway
The framework does not eliminate judgment. It structures the conditions under which judgment is applied. That is a meaningful difference when P0 events are running in parallel, when key evidence sources are delayed, and when the business expects a credible, transparent and defensible triage decision quickly.
The key principle embedded in the framework is this: if the technology is affected and invocation cannot be ruled out, remediation is required. External exposure determines the speed. Context determines the strength of interim controls and the depth of assurance required before the organization can close the triage.
The teams that move fastest through P0 events are not the ones with the most analysts. They are the ones with the clearest questions. These three, asked in sequence, are a good place to start.
Cyber Second Line of Defense covers cybersecurity risk and strategy for security leaders. Subscribe to get new posts.